
A familiar problem sits behind many document platforms. Legal teams want proof of integrity. Security teams want less sensitive data crossing networks. Product teams want a workflow users will tolerate. Those goals often collide the moment an API asks clients to upload the entire file just to prove that a file exists, hasn’t changed, or matches a prior record.
That’s why we hash documents locally and only send metadata to the API. In practice, this design cuts unnecessary exposure, keeps the original file under the user’s control, and still gives auditors, verifiers, and downstream systems a reliable way to check integrity. For CTOs, CISOs, and compliance leads, it’s not just a cryptography choice. It’s a system design decision that changes breach impact, privacy posture, and operational overhead.
Table of Contents
- What Is Document Hashing A Primer on Digital Fingerprints
- The Local Document Hashing Workflow Explained
- The Core Principle Why Only Metadata Is Transmitted to the API
- Security and Compliance Benefits in Regulated Industries
- Traditional File Uploads vs Metadata-Based Verification
- How Blocsys Builds Secure Document Authentication Systems
- Frequently Asked Questions About Local Document Hashing
What Is Document Hashing A Primer on Digital Fingerprints
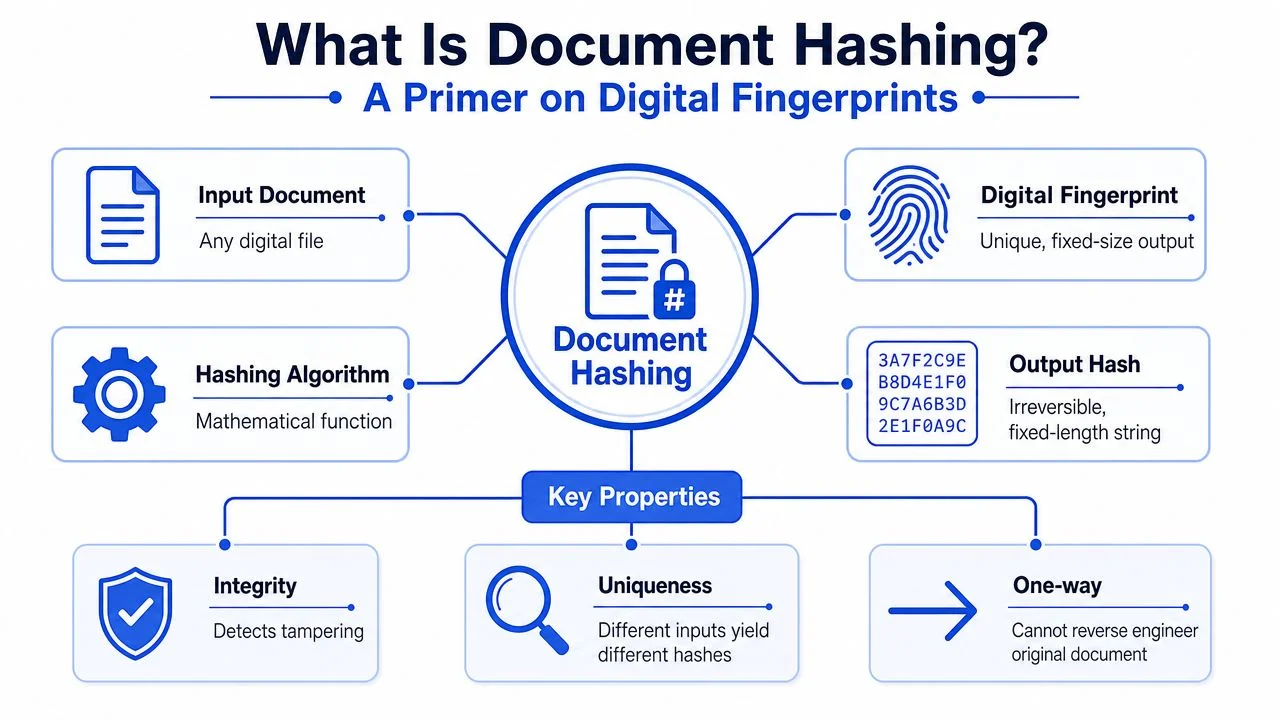
A document hash is a fixed-length cryptographic output generated from a file. The simplest way to explain it is this. It’s a digital fingerprint for the document. If the file changes, even slightly, the fingerprint changes too.
That makes hashing useful when you need to prove integrity without revealing content. A lender can confirm that a submitted statement is the same statement reviewed earlier. A hospital can check that a record hasn’t been altered in transit. A legal platform can anchor proof of a contract version without passing the contract through every verification service in the stack.
Why a hash works as a stand in for the file
A good hashing function has a few properties enterprise teams care about:
- Deterministic output. The same file produces the same hash every time.
- One-way behaviour. You can calculate a hash from a file, but you can’t reconstruct the file from the hash.
- Tamper detection. If someone edits the file, the resulting hash no longer matches.
- Practical uniqueness. Different files are expected to produce different outputs, which is what lets systems use hashes as reliable identifiers in verification flows.
Practical rule: If your system only needs to prove sameness, integrity, or prior existence, it often needs the hash, not the document body.
For teams dealing with PDFs and Office files, deterministic preprocessing matters as well. Formatting quirks, embedded fields, and export behaviour can affect repeatable hashing, which is why canonicalisation for PDF and Office file hashing becomes important in production systems.
Why this matters at document scale
This pattern becomes more valuable as document volume increases. In India, DigiLocker crossed 100 million registered users by 2023, and the Ministry of Electronics and IT reported that more than 5.7 billion documents had been issued in DigiLocker by 2024, illustrating how quickly digital document ecosystems grow when workflows move online, as described in Acronis guidance on notarising by hash without metadata.
At that scale, transmitting every full document through every verification step is wasteful and risky. Hashing locally before sending only what the receiving system needs reduces payload size and limits exposure of the original content. That’s the practical foundation of privacy-first verification.
The Local Document Hashing Workflow Explained
The cleanest implementation starts on the user’s device. The browser, mobile app, desktop client, or internal workstation receives the file selection and processes the document before any network call sends verification data upstream.
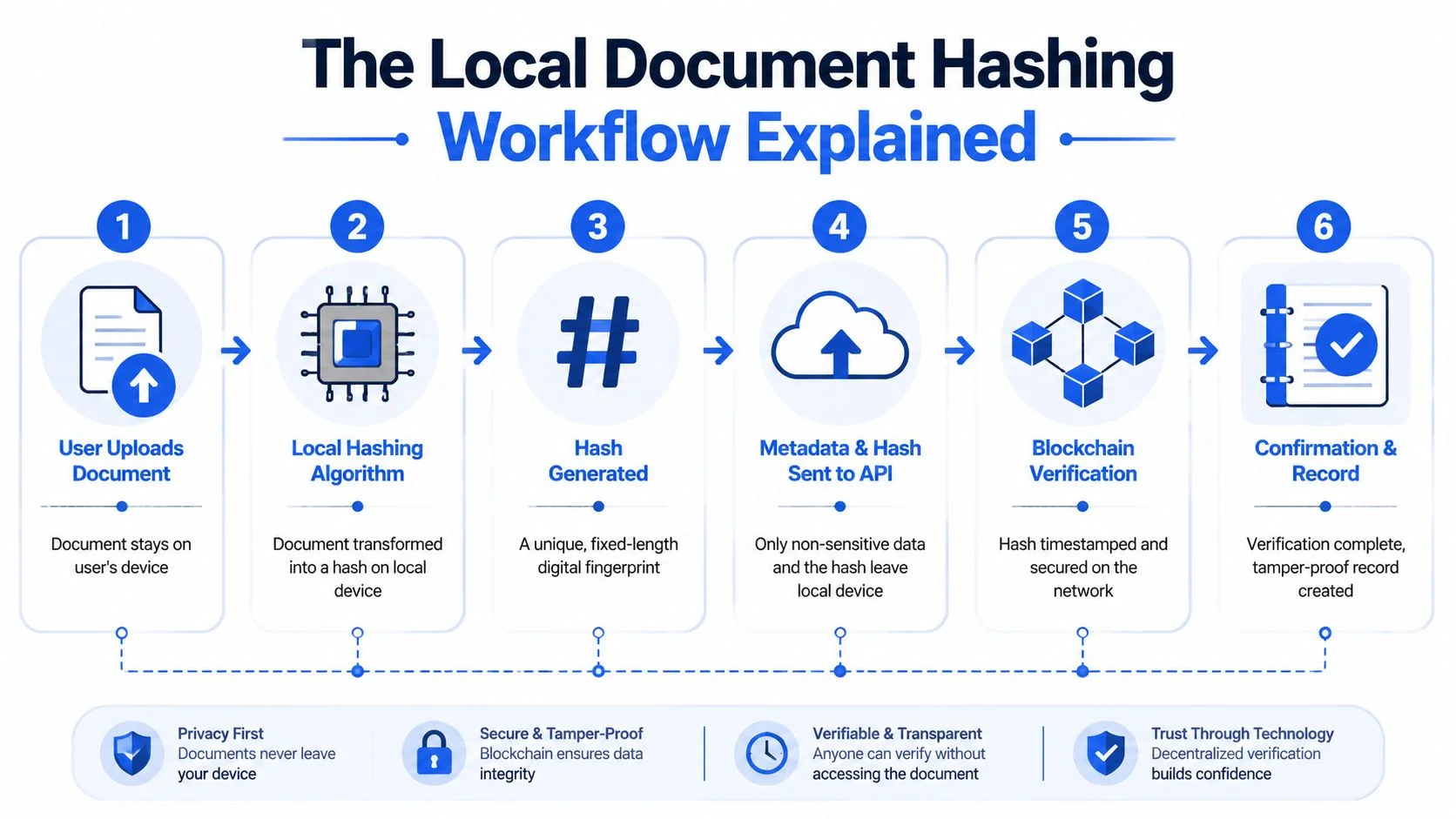
What happens on the client side
The document is chosen locally. The client then computes a cryptographic digest, commonly SHA-256 or an equivalent approved algorithm, across the file contents. That computation happens in the browser runtime, native app, or trusted local service.
At the same time, the application prepares a small metadata object. This usually includes operational context such as document type, workflow stage, file size, or a non-sensitive internal reference. It should exclude anything confidential.
After that, the client sends a lightweight API request containing the hash and the metadata. The original file remains where it started unless a separate business process explicitly requires storage or exchange outside the verification service.
A useful reference for engineering teams is data pipeline architecture for security-sensitive systems, because the hashing pattern only works well when the ingestion path, event handling, and audit trail are designed around minimal disclosure.
The workflow below shows the model visually.
What the API should and should not receive
Acronis is explicit about a point many teams miss. In its notarisation flow, the file hash goes to the API, while metadata is submitted separately as JSON, and it warns against placing sensitive information in metadata because the full metadata object is exposed, as shown in Acronis guidance on notarising by hash with metadata.
That warning matters. Metadata is often treated casually by developers because it feels secondary. It isn’t secondary. It’s data your API exposes, stores, logs, indexes, and sometimes replicates.
A practical implementation standard looks like this:
- Hash locally first. The client computes the digest before any transmission.
- Sanitise metadata. Keep only non-sensitive descriptive fields needed for workflow logic.
- Send the smallest useful payload. Hash, file type, size, timestamp, and a controlled business reference are usually enough.
- Keep the file outside the verification API. If another service stores the file, isolate that concern from the proof and verification layer.
Treat metadata as visible operational context, not as a hidden annex for sensitive content.
The Core Principle Why Only Metadata Is Transmitted to the API
The central security principle isn’t speed. It’s data minimisation. If an API can verify a claim without receiving the original file, asking for the file creates avoidable risk.
That matters in every threat model. Web application flaws, misconfigured storage, compromised service accounts, over-permissive logs, and careless support access all become more damaging when the platform collects raw documents by default. If the API stores only a hash and limited metadata, a breach still matters, but the attacker does not automatically obtain contracts, records, passports, medical reports, or board materials.
Data minimisation is the real design rule
Secure architecture transforms into a business decision. Leaders often evaluate verification systems in terms of features. Security teams evaluate them in terms of exposure. Those aren’t the same thing.
With local hashing, the API becomes a proof-processing service rather than a document-collection service. That distinction simplifies reviews because the system no longer needs broad justification for ingesting document bodies in flows that only require integrity checking, deduplication, timestamping, or proof anchoring.
A related design choice appears in xAPI’s attachment model, where the SHA-2 hash of file contents binds a file to its metadata record, and the file itself can be optional if a URL or hash-based reference exists, as explained in xAPI’s attachment deep dive. That model is useful because downstream systems can compare hashes exactly, without repeatedly moving or reprocessing the file itself.
Metadata is useful but it is not harmless
Modern platforms treat metadata as a first-class operational layer. That helps with analytics, indexing, and retrieval. It also creates a quiet trap. Teams start adding searchable business context until metadata becomes another sensitive dataset.
The right discipline is narrow metadata plus immutable linkage by hash. If you need a direct comparison of architecture choices, centralised vs blockchain-based document verification is a useful lens, because both models benefit from reducing what the verification API sees.
A secure verification service should know enough to verify the document, not enough to reconstruct the business transaction behind it.
What doesn’t work is overloading metadata with customer notes, legal annotations, health context, or free-form descriptions. Once metadata enters APIs, logs, search layers, and integrations, it becomes part of the attack surface.
Security and Compliance Benefits in Regulated Industries
Regulated organisations usually approve this pattern for a simple reason. It aligns technical design with privacy obligations. When a system processes less personal or confidential material, compliance reviews become more focused and the consequences of control failures are narrower.
Why regulated teams approve this pattern faster
For GDPR, HIPAA, CCPA, the UK data protection regime, Singaporean privacy controls, and similar frameworks, the recurring question is whether you’re processing only what is necessary. Hash-first verification supports that principle directly.
India provides a concrete example of why metadata-only API calls fit security-sensitive systems. The Aadhaar ecosystem has performed over 100 billion authentication transactions cumulatively, and India’s Digital Personal Data Protection Act was enacted in 2023, reinforcing the need to minimise personal-data transmission, as discussed in Zuplo’s API security article that references this pattern. In practical terms, a non-reversible fingerprint plus limited metadata reduces breach impact, lowers bandwidth use, and supports faster checks while maintaining audit value.
That logic carries well beyond India. European and North American review teams often use different legal language, but the architectural preference is similar. Don’t move sensitive records unless the business process requires it.
For organisations modernising verification stacks alongside broader platform hardening, it’s also worth reviewing adjacent patterns such as cloud-native security for CEFs, particularly where document verification sits inside larger regulated digital infrastructure.
How this looks in banking healthcare and government
A bank can validate that the income statement presented during underwriting is the same statement approved by an earlier reviewer, without routing the raw file through every supporting API. The lending platform still gets proof of integrity. The verification service doesn’t become a shadow document vault.
A healthcare provider can use the same model to confirm that a discharge summary or lab report hasn’t been altered between systems. The operational metadata can describe the record type and timestamp while keeping patient content out of the verification interface.
Government and education workflows benefit for the same reason. Verified certificates, identity documents, and administrative records often move across many systems and vendors. Hash-based verification lets agencies preserve evidentiary integrity without turning each integration point into a repository of sensitive files.
Traditional File Uploads vs Metadata-Based Verification
The local-hash model is immediately understood once it is compared to the legacy alternative. Traditional uploads ask the verification service to receive, inspect, store, and protect the full document. Metadata-based verification asks the service to verify proof while the file stays elsewhere.
Comparison for enterprise decision makers
| Criterion | Traditional File Upload | Local Hashing & Metadata Verification |
|---|---|---|
| Security risk | Centralises sensitive files inside the verification layer. A compromise exposes document contents. | Limits the verification layer to hashes and controlled metadata. Breach impact is narrower. |
| Privacy exposure | The service sees the entire document even when it only needs proof of integrity. | The service receives only the minimum useful data for identification and checking. |
| Performance and speed | Larger payloads take longer to transfer and process. | Small requests are lighter and easier to handle at scale. |
| Bandwidth and storage cost | Repeated file transfers and retention increase infrastructure burden. | Hashes and metadata reduce transfer overhead and avoid unnecessary duplication. |
| Compliance burden | More justification, retention controls, and access management are needed because raw documents are in scope. | Reviews are simpler because the verification component handles less sensitive material. |
| Auditability | Possible, but often coupled to file storage complexity. | Strong, because the hash acts as the immutable linkage key for later comparison. |
This comparison also changes how blockchain-backed systems should be designed. If you’re anchoring proofs on-chain or batching evidence for many files, Merkle batching for proof-heavy systems becomes the next logical optimisation after local hashing.
The important trade-off is honesty about what this model does not do. It doesn’t eliminate the need to secure the original file wherever it lives. It separates concerns. The document repository protects content. The verification API proves integrity. Teams that mix those responsibilities usually end up with a more complex and riskier platform.
How Blocsys Builds Secure Document Authentication Systems
A fintech compliance team approves a verification rollout only after one question is answered clearly. Can the system prove a document is authentic without pulling regulated content into another API boundary? In healthcare, the same question comes from privacy counsel and security architecture, because every extra copy of a file expands review scope, retention obligations, and incident impact.
That is the design point Blocsys builds around. The hashing logic, metadata policy, audit trail, and proof model are specified as one system, not as separate features owned by different teams. Client-side hashing on its own is not enough. If metadata is loosely defined or evidentiary records are inconsistent, the control fails at the point auditors, investigators, or counterparties need it most.
What a production ready architecture usually includes
A production implementation starts with deterministic preprocessing on the client, followed by local hashing and a metadata schema that blocks sensitive fields before any request leaves the user environment. The verification layer then records the digest, timestamp, policy-relevant context, and the result of each verification event in a form that downstream systems can consume without touching the source file.
That architecture matters for enterprise sign-off. Security teams want fewer systems handling raw content. Compliance teams want a narrower data footprint and clearer control boundaries. Product teams want a model that can support document-intensive AI and Web3 workflows without turning the verification service into a shadow document repository.
If blockchain proofing is part of the design, the chain should store proof references tied to the digest, not the document itself. The same rule applies whether the workflow covers legal records, payment operations, clinical documentation, credentials, or tokenised asset files. For teams designing automated proof flows, smart contract-based document authentication workflows show how verification logic can be executed while the underlying file remains under the owner’s control.
Blocsys Technologies works in this area on blockchain and AI-backed document infrastructure for environments where tamper evidence, privacy controls, and auditability all have to hold up under review.
The implementation mistake I see most often is architectural drift. A team adds local hashing, but the API still accepts full uploads for convenience, support cases, or legacy integrations. That decision usually reintroduces the same exposure the new design was meant to remove. A cleaner model keeps content custody with the repository of record and limits the verification service to proving integrity, recording events, and returning results that stand up in regulated operating environments.
Frequently Asked Questions About Local Document Hashing
Can you verify integrity without uploading the file
Yes. If both parties can compute or compare the same document hash, they can confirm whether the file matches an expected version. That’s the core reason the pattern exists.
What metadata is safe to send
Send only non-sensitive operational fields needed for the workflow. Typical examples include document type, file size, timestamp, or an internal reference that doesn’t reveal private content. Avoid putting secrets, personal details, or free-form notes into metadata.
Does blockchain change the hashing model
No. Blockchain usually strengthens the proof model by anchoring or timestamping the hash. It does not remove the need to hash locally first or the need to keep raw documents out of the verification API when full-file transmission isn’t required.
Who should own the hashing logic
The client side should own the hashing logic when privacy is the priority. That can be a browser application, mobile app, desktop client, or controlled local agent. The important point is that the digest is created before the verification request leaves the user’s environment.
Is metadata-only verification always the right answer
No. Some workflows require secure file storage, content inspection, fraud analysis, or legal exchange of the underlying document. In those cases, upload may still be necessary. The design question is narrower. If the service only needs proof of integrity, don’t force it to ingest the whole file.
What is the main implementation mistake
Teams often protect the file and then leak business-sensitive information through metadata, logs, or debug traces. The rule is simple. Minimal metadata, strict schema control, and no assumption that metadata is private.
If your team is designing a privacy-first document verification workflow, Blocsys Technologies can help assess the architecture, define the local hashing and metadata model, and build the surrounding proof, audit, and blockchain integration layers in a way that fits regulated enterprise use cases.