Teams usually arrive at Merkle batching after the same failure mode. They start by anchoring one proof per document, certificate, event, or compliance record. The first prototype works. The verifier can check a transaction hash, the smart contract is simple, and the reasoning feels clean. Then volume arrives and the design breaks on cost, queue depth, and operational noise.
A document platform issuing daily credentials, a fintech exporting audit evidence, or a logistics stack signing handoff records all hit the same constraint. Public chains are good at final settlement, not at carrying every raw assertion individually. If you try to write each proof on-chain, you pay for repetition that adds no new trust.
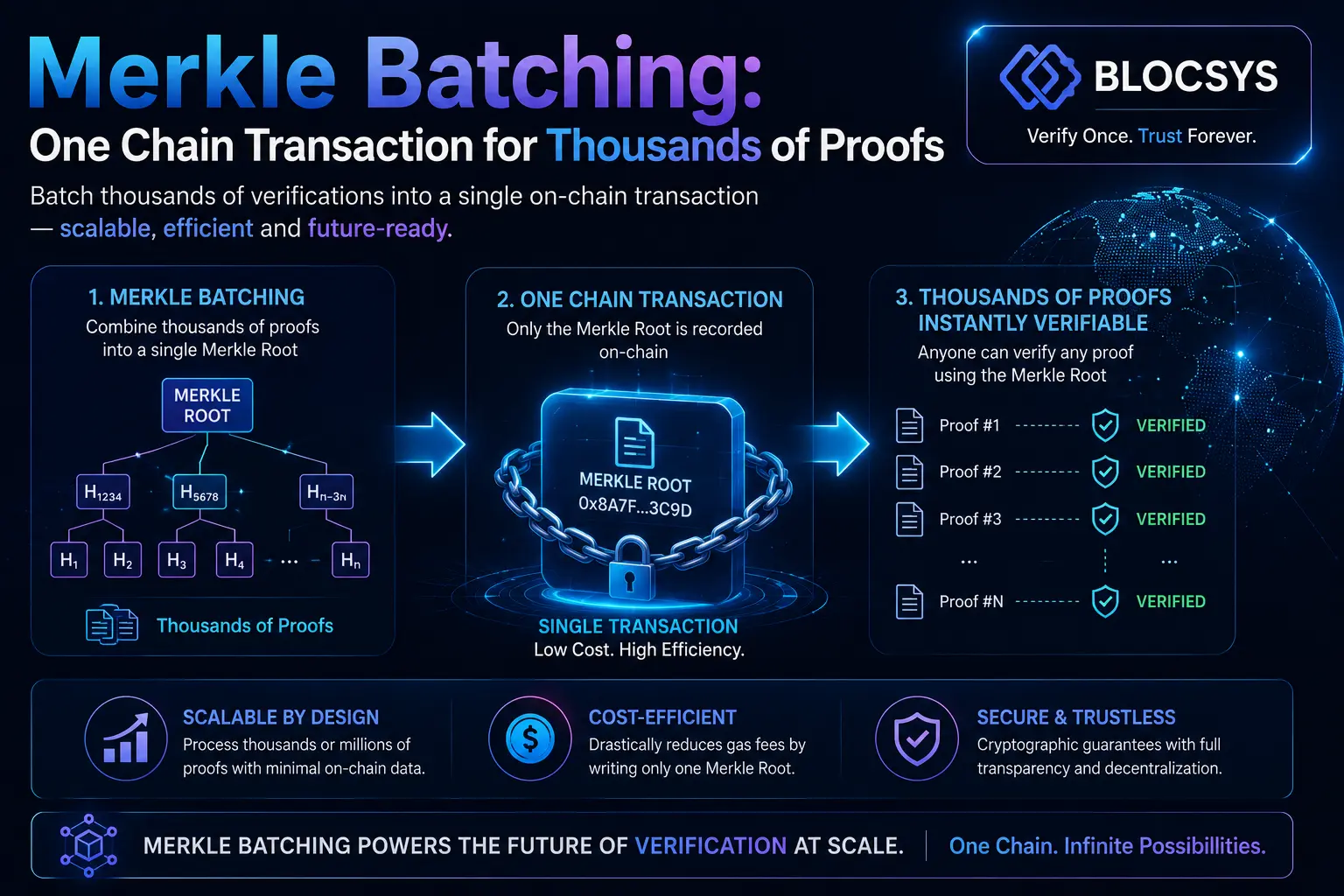
That’s where Merkle batching becomes an architecture choice rather than a cryptography lesson. The model is simple. Hash each item off-chain, build a Merkle tree from those hashes, anchor only the Merkle root on-chain, and hand each verifier a compact inclusion proof. One chain transaction can authenticate thousands of underlying records without storing those records on-chain.
The phrase Merkle batching one chain transaction for thousands of proofs describes the practical outcome, but the core engineering work sits in the pipeline around it. Hash determinism. Canonicalization. Batch windows. L2 anchoring. Proof state management. Verification APIs. Evidence packaging. Re-anchoring for document updates. Those decisions determine whether the system is cheap, auditable, and usable by other teams.
If you’re building proof infrastructure, it also helps to look at adjacent thinking around leveraging blockchain for efficiency because the useful question isn’t whether blockchain can attest to data. It’s where to place the chain boundary so you only commit the minimum trustworthy state.
Table of Contents
- Introduction
- The Foundational Problem of On-Chain Transaction Costs
- Core Architecture How Merkle Batching Aggregates Proofs
- The End-to-End Proof Batching Pipeline on Polygon L2
- Developer Integration Workflows and Verification APIs
- Advanced Considerations for Enterprise-Grade Systems
- Implementing Scalable Proof Systems with Blocsys
- Frequently Asked Questions about Merkle Batching
Introduction
Most engineering teams don’t need a tutorial on what a Merkle tree is. They need a design that survives production traffic, legal review, and verification by third parties who weren’t present when the original file was created.
In practice, the system has to do more than generate a root. It has to produce a keccak-256 document hash consistently across environments, canonicalise files before hashing, retain enough metadata to rebuild evidence later, and expose a verification flow that doesn’t force auditors or customers to trust your database. That’s the difference between a demo and a blockchain attestation system.
The architectural target is narrow and useful. Keep raw documents and sensitive business data off-chain. Put only a compact commitment on-chain. Make every downstream proof portable. Let another party validate inclusion against the chain without asking your platform for permission.
Practical rule: If your verifier needs your database to decide whether a proof is valid, you haven’t finished the architecture.
The rest of the design follows from that rule. A hash-only proof API should accept canonical hashes rather than raw files whenever possible. A proof batching pipeline should collect leaves into predictable batch windows. A Polygon L2 attestation contract should anchor roots cheaply enough that the anchoring cadence matches business needs, not just network prices. And your verification layer should return self-contained evidence bundles, not opaque references.
The Foundational Problem of On-Chain Transaction Costs
Why naive proof anchoring fails quickly
A team ships a document attestation feature, sends one blockchain transaction per record, and the first pilot looks fine. Then volume arrives. A few thousand certificates, shipment events, or compliance records later, the design starts failing in the places that matter: fee predictability, operational throughput, and reconciliation.
The problem is not only gas price volatility. Every single anchor creates another unit of blockchain operations work. Someone has to queue transactions, handle nonce ordering, retry failed submissions, track finality, and explain gaps when business records and chain state drift out of sync. At scale, the anchoring layer becomes its own subsystem.
That is the wrong place to spend engineering time. The chain should act as a compact trust anchor, not as a write path for every business event.
What you actually pay for
On-chain cost comes from three separate choices. How often you submit transactions. How much data each transaction carries. How much contract execution you require at verification time.
That distinction matters because teams often optimize the wrong layer. They reduce contract logic but still send one transaction per proof. Or they batch submissions but design verification flows that push large proofs on-chain for routine checks. Both patterns keep the cost curve too close to proof volume.
For high-volume attestation systems, the practical baseline is straightforward:
- Write one batch commitment on-chain: Store the Merkle root, batch identifier, and minimal indexing data.
- Keep proof verification off-chain for normal workflows: Auditors, customers, and counterparties can validate inclusion locally against the anchored root.
- Use on-chain verification only for dispute or settlement paths: Pay execution costs when the chain must adjudicate state, not when someone just needs evidence.
Network selection transitions into an architecture decision, not merely a deployment detail. If root anchoring happens every few minutes or every batch window, execution cost directly shapes your batching cadence, customer SLAs, and backlog behavior. For teams assessing lower-cost execution environments, this overview of Layer 2 solutions for blockchain scalability is a useful framing for the trade-off.
The production trade-off
Merkle batching improves the economics because it breaks the direct link between proof count and transaction count. Ten proofs and ten thousand proofs can share the same anchor pattern if they fit the same batch policy.
That gain is real, but it is not free.
You are replacing on-chain repetition with off-chain discipline. The system now needs deterministic batch construction, durable storage for leaves and proofs, replayable root generation, and evidence packaging that survives audits months later. The engineering trade is usually worth it because off-chain compute and storage are cheaper to scale than public chain writes, but the complexity does move into your pipeline.
| Design choice | What it buys you | What it costs you |
|---|---|---|
| One proof per transaction | Simple implementation at very low volume | Fees scale linearly, plus noisy transaction operations |
| Merkle root anchoring | Thousands of proofs can share one chain write | Batch building, proof generation, and evidence retention move off-chain |
| Frequent on-chain proof verification | Contract-level settlement and enforcement | More calldata, more execution cost, and tighter contract design constraints |
| Off-chain verification against an on-chain root | Low-cost validation for auditors and counterparties | Verification UX and proof packaging must be designed carefully |
A good rule in production is to treat on-chain writes as scarce and verification requests as common. Once you design around that assumption, batching stops looking like an optimization and starts looking like the only cost model that holds under real traffic.
Core Architecture How Merkle Batching Aggregates Proofs
Start with deterministic document hashes
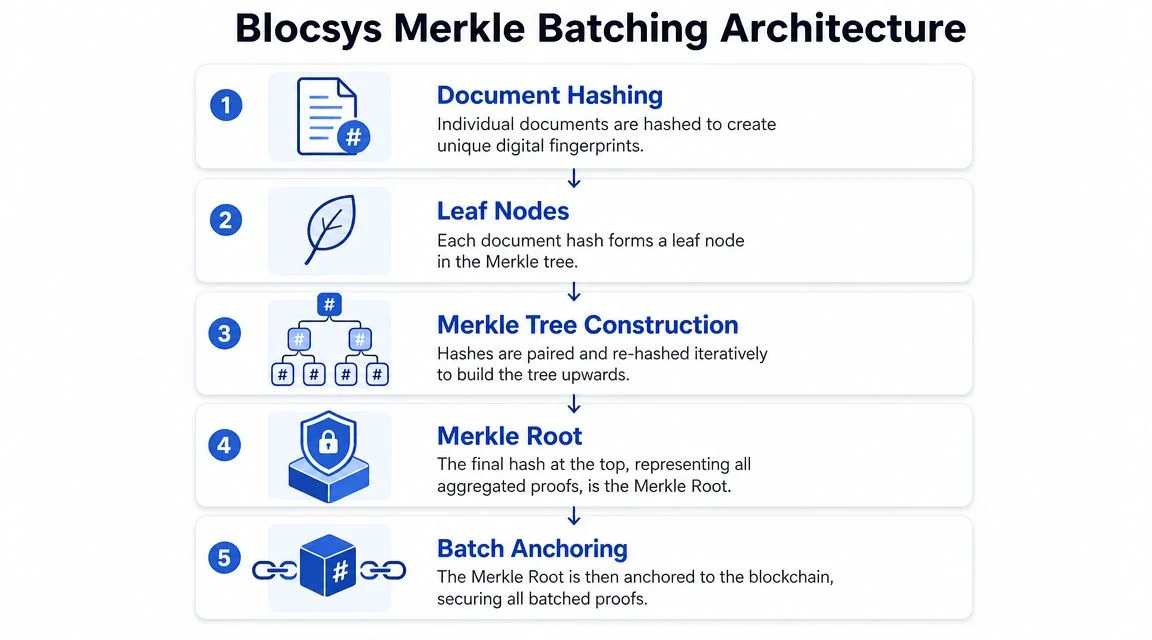
A Merkle tree is only as trustworthy as the leaf generation process. For document systems, that means client-side keccak-256 hashing and deterministic file preprocessing.
You don’t want the server inventing the canonical representation of a document after upload if the client, the auditor, or a third-party verifier can’t reproduce it later. The safer pattern is:
- Canonicalise the file locally.
- Hash the canonical byte stream with keccak-256.
- Submit the hash and minimal metadata to a hash-only API.
- Store the canonicalization recipe with the proof record.
Many implementations frequently become fragile. Different renderers and exporters can produce semantically identical files with different bytes. If you hash raw bytes without normalisation, your blockchain integrity verification depends on incidental formatting.
For common formats, the canonicalisation rules should be explicit:
- PDF: Strip unstable metadata where your workflow allows it, normalise byte ordering policies, and define whether embedded signatures are part of the hashed view.
- OOXML: Unzip, order internal parts deterministically, exclude unstable timestamps if your policy permits, then hash the reconstructed canonical package.
- XML: Apply exc-c14n normalization before hashing so namespace and attribute serialisation differences don’t change the result.
- JPEG and PNG: Decide whether metadata blocks are included. If not, remove them consistently before hashing.
A proof system fails quietly when two honest parties hash the same document differently.
Build the tree once and keep the leaves stable
After hashing, each hash becomes a leaf in the Merkle tree blockchain architecture. The batching service sorts or positions leaves according to a declared policy, then hashes pairs upward until a single root remains.
The critical discipline here is to define the tree rules once and never improvise them later. Engineers should document:
- Leaf ordering policy
- Duplicate hash handling
- Odd-node pairing rule
- Hash function and byte encoding
- Batch identifier and timestamp policy
If those rules drift between SDK versions, merkle proof verification breaks across environments even when the on-chain root is correct.
The historical model is well established. Bitcoin uses Merkle trees in block headers and supports Simplified Payment Verification, where a node can verify a transaction by requesting a Merkle proof instead of downloading all block transactions. The Merkle root in the header summarises the full block in 32 bytes, as explained in Binance Academy’s overview of Merkle trees and roots.
That same compression principle is why merkle root anchoring works for document systems.
Why inclusion proofs stay small
The useful property of Merkle batching is that proof growth is logarithmic, not linear. As discussed in this explanation of Bitcoin-style inclusion proofs, a verifier doesn’t need every transaction in the set. It only needs the target item plus a logarithmic-size proof. For a million transactions, a Merkle proof needs about 20 helper hashes, and for a billion transactions it needs about 30 helper hashes. The root itself is only a 32-byte hash summarising the full set.
That’s the reason one chain transaction can stand in for thousands or even millions of underlying proofs. In a multi-document proof architecture, the chain stores one commitment. Every individual document carries a compact path back to that commitment.
For engineers planning adjacent privacy or compression layers, it’s worth understanding how this differs from more advanced proving approaches such as zero-knowledge proofs in blockchain systems. Merkle batching gives cheap inclusion and integrity proofs. It doesn’t hide the existence of a leaf or prove richer statements about private state.
The End-to-End Proof Batching Pipeline on Polygon L2
A production system needs a pipeline, not just a tree builder.
Pipeline stages from file to anchor
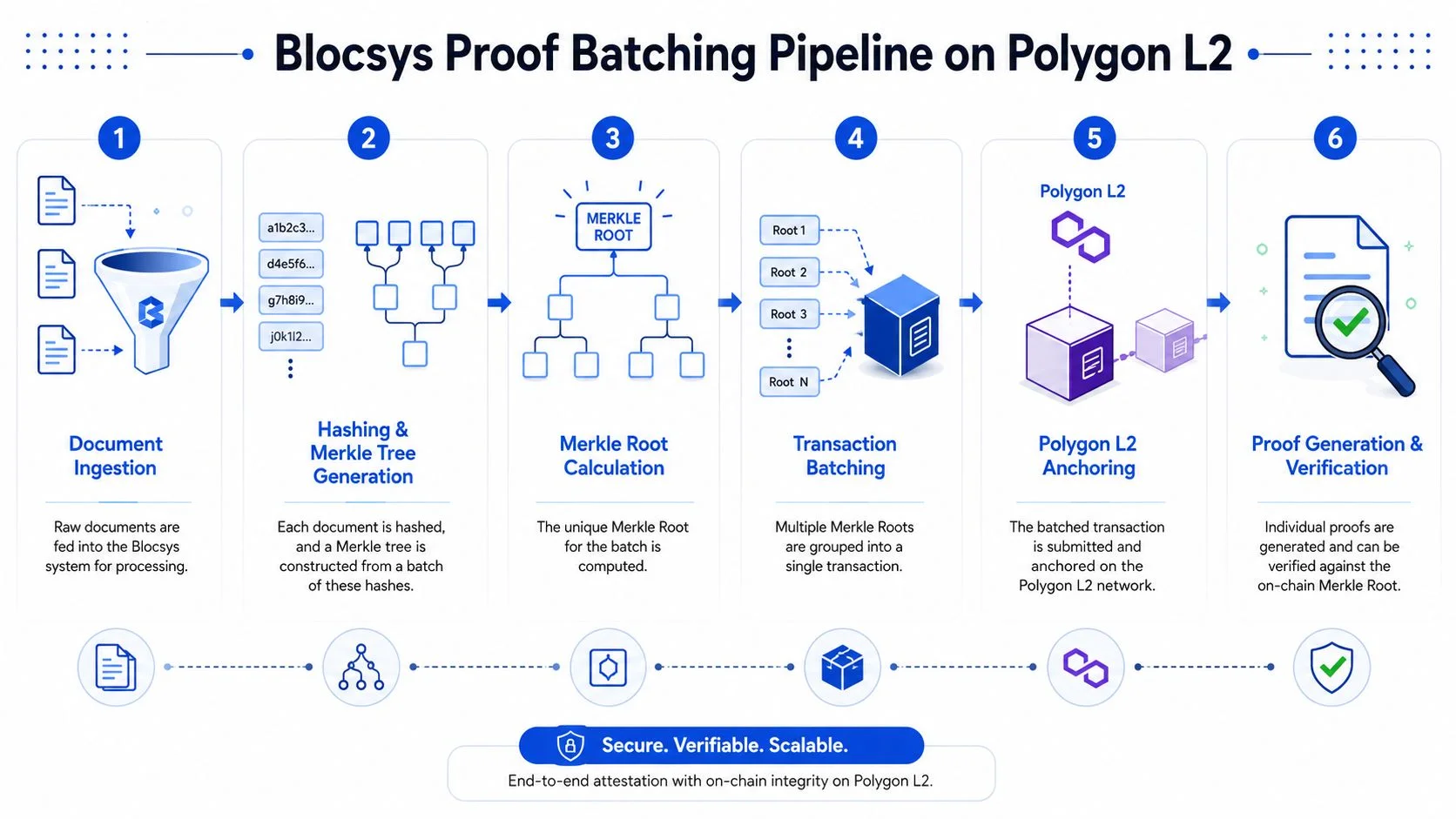
A reliable blockchain anchoring pipeline on Polygon L2 usually looks like this:
Document ingestion
The client application receives the file or event payload. In browser workflows, the SDK should hash locally where possible. In backend workflows, Node.js workers should apply the same canonicalisation and hashing rules.Hash-only submission
The client sends the keccak-256 document hash and supporting metadata to the service. Raw documents can live in object storage such as S3, but the proof service should operate on hashes and canonicalization metadata, not file contents, whenever possible.Batch assembly
The batcher groups pending leaves into a tree. The grouping policy might be time-based, count-based, or urgency-based depending on your SLA for proof availability.Merkle root generation
The service computes the root and stores the full tree artefacts needed for later inclusion proof generation.Polygon L2 anchoring
A single transaction submits the root to a smart contract. The contract doesn’t need the entire batch. It only needs enough information to record an immutable commitment and any application-specific identifiers.Proof issuance
For each leaf, the system generates an inclusion proof and binds it to the anchor transaction reference.Verification
External parties can verify the document hash, the Merkle path, and the root’s on-chain existence.
A good supporting principle is to keep the batcher asynchronous. User-facing applications shouldn’t wait on the chain. They should wait on receipt, then poll or subscribe for status updates.
Later in the delivery lifecycle, teams often benefit from a broader data pipeline architecture review because proof systems inherit all the usual pipeline concerns: queue durability, idempotency, replay safety, and traceability.
Proof state machine and auditability
A proof state machine makes the system legible to operators and auditors. The states vary by implementation, but the pattern is stable:
| State | Meaning |
|---|---|
| Received | Hash accepted and stored |
| Canonicalized | File normalisation completed or validated |
| Queued | Ready for batch inclusion |
| Batched | Assigned to a specific Merkle tree |
| Anchoring | Root transaction submitted |
| Anchored | Transaction confirmed and root available |
| Verifiable | Inclusion proof generated and published |
| Superseded | Later version exists in lineage graph |
This model solves several real problems. It lets support teams answer “where is my proof?” without touching chain internals. It lets compliance teams demonstrate processing order. And it creates clean hooks for retries when anchoring fails but the batch itself is still valid.
Where Polygon L2 fits
Polygon L2 is a practical place to anchor roots when the system needs low-cost, frequent attestations. The chain becomes the settlement and timestamp layer, while the heavier proof lifecycle remains off-chain.
The historical basis for this pattern goes back to Bitcoin’s block-header Merkle roots and SPV. The design proved that compact commitments can support lightweight verification. The same logic carries into modern proof infrastructure. Ethereum’s documentation also shows the limit: proving 1,024 words with a Merkle proof requires 10 layers and about 6,380 gas, which means proofs are compact but not free to verify on-chain, as noted in the earlier discussion sourced from Binance Academy’s Merkle tree explainer.
Here’s a visual walkthrough of the anchoring flow before verification moves back off-chain:
For most enterprise workloads, that leads to a simple rule. Anchor frequently enough to meet your audit and freshness requirements, but don’t turn the chain into your primary query engine.
Developer Integration Workflows and Verification APIs

Browser and Node.js SDK patterns
A TypeScript proof SDK should behave consistently in both browser and Node.js environments. The browser path is useful when the user or issuer wants local hashing before upload. The Node.js path is useful for server-side ingestion, scheduled batch jobs, and integration with existing document systems.
A typical browser workflow:
- Canonicalise the selected file in the client
- Compute the hash locally
- Submit the hash to the proof API
- Receive a proof job identifier
- Poll for evidence bundle readiness
A typical Node.js workflow:
- Pull documents from S3 or an internal queue
- Canonicalise by file type
- Hash with the same keccak-256 rules as the browser SDK
- Submit hashes in bulk for batch proof submission
- Store returned proof identifiers alongside business records
The most important design choice is parity. The same file must produce the same leaf regardless of environment.
For teams building Solidity-facing tooling around these anchors, contract upgrade and interface design still matter. Verification registries and attestation contracts should be versioned carefully, especially if you rely on upgrade patterns such as those discussed in proxy contract design in Solidity.
Evidence bundle design
The proof artefact should be portable. That means packaging more than a Merkle path string.
A useful blockchain evidence bundle contains:
- Document hash: The canonical keccak-256 hash
- Canonicalization metadata: Enough information to reproduce the hash
- Merkle proof: Sibling hashes and positional data
- Merkle root: The batch commitment
- Anchor reference: Chain, contract address, and transaction identifier
- Batch metadata: Batch ID and creation policy details
- Lineage pointer: Optional reference to prior or superseding versions
This makes document proof verification independent of your production database. A customer, auditor, or partner can keep the evidence bundle and verify later even if your application has changed.
Verification rule: Treat the evidence bundle as the product, not the transaction hash.
Verification API shape
A blockchain proof verification API should accept either a raw document plus evidence bundle or a precomputed hash plus evidence bundle. It should return a machine-readable result with explicit failure modes.
Good result categories include:
- Hash mismatch
- Proof path invalid
- Root mismatch
- Anchor not found
- Anchor found but contract untrusted
- Valid and anchored
Avoid APIs that only return a boolean. Verifiers need to know what failed.
A compact request model might look like this in prose:
- Client submits file or canonical hash.
- API derives or validates the document hash.
- API recomputes the root from the Merkle path.
- API checks the on-chain anchor.
- API returns a signed verification report or plain JSON result.
That’s enough to support decentralized proof verification while keeping your service useful as an orchestration layer rather than a trust bottleneck.
Advanced Considerations for Enterprise-Grade Systems
When bigger batches stop helping
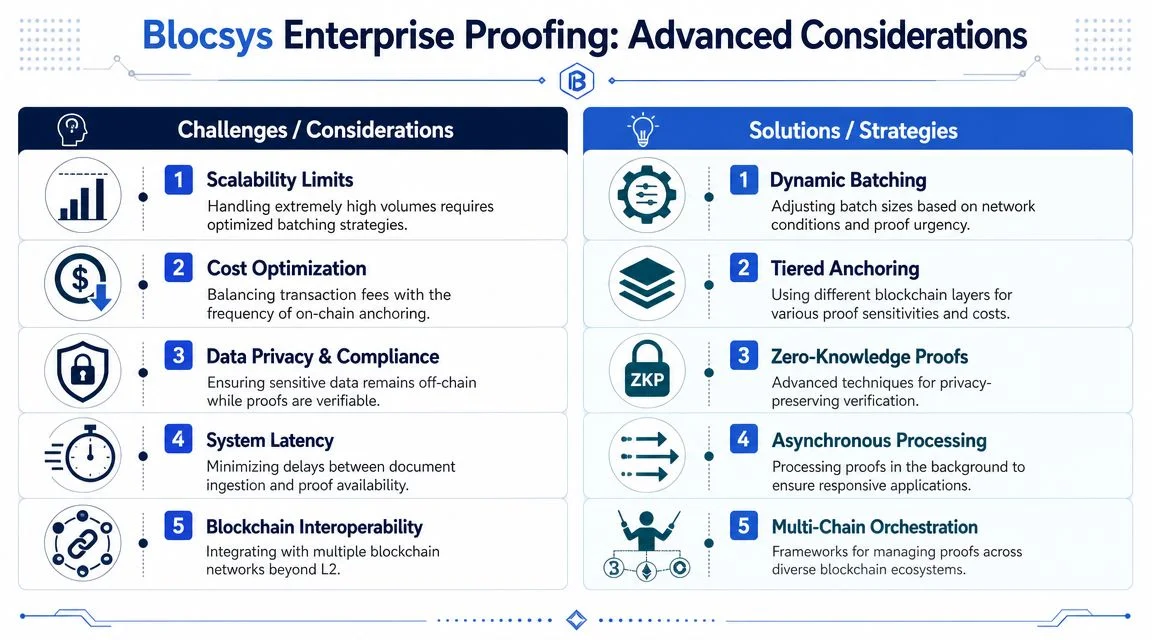
A team usually notices the actual limits of Merkle batching after the first successful launch. The root anchoring cost looks good on a spreadsheet, then support tickets arrive because proofs take too long to issue, downstream systems choke on proof payload size, or a delayed anchor breaks an SLA that mattered more than gas savings.
Batch size is a policy decision, not just a compression trick.
The trade-off is straightforward. Larger batches reduce the number of chain transactions, but they increase waiting time before a document becomes provable against a final anchored root. They can also push more data into proof distribution and verification paths if downstream consumers need full inclusion proofs, not just a receipt from your API. In systems with contractual issuance windows, that delay is often more expensive than the extra anchor transaction.
The practical sizing questions are usually these:
- Freshness window: How long a document can wait before its proof must be available
- Verification path: Whether verifiers stay off-chain or submit proof data into contracts
- Payload budget: How much proof material client apps, partner APIs, or auditors can realistically carry
- Retry cost: What happens operationally if an anchor attempt fails and the batch has to be rebuilt or replayed
For high-volume issuance, I usually prefer bounded batches with clear close conditions, such as max leaf count, max wait time, or both. That keeps proof latency predictable and makes incident handling less painful. A giant open batch can look efficient until one stuck transaction holds thousands of records in a pending state.
Concurrent updates and mutable proof sets
Production systems rarely batch from a quiet, ordered stream. They batch from multiple writers, retries, late arrivals, and document corrections happening at the same time.
That changes the design problem. The hard part is not building a tree. The hard part is defining when a leaf is eligible for a batch, when a batch becomes immutable, and how clients know which root their proof belongs to.
A useful reference point is Solana’s discussion of concurrent Merkle tree patterns, which focuses on accepting multiple updates while preserving a valid view of state in high-throughput environments. The lesson for proof systems is simple. If your intake layer allows concurrent writes, your batching service needs explicit snapshot rules, idempotent job handling, and proof issuance tied to a finalized batch version, not to whatever happened to be in memory when the request arrived. Helius explains some of that design pressure in its overview of concurrent Merkle trees and blockchain cryptographic tools.
Stable snapshots are easy. Concurrent proof issuance under active writes is where architecture earns its keep.
In practice, that usually means a few concrete controls:
- Append-only intake log so batch assembly can be replayed deterministically
- Batch sealing rules so no leaf enters a batch after the root is computed
- Idempotency keys on submission APIs to prevent duplicate leaves during retries
- Proof status states such as received, batched, anchored, failed, and superseded
- Versioned canonicalization policy so a hash generated today can still be explained a year later
Without those controls, the failure mode is subtle. Two services can both be correct locally and still issue conflicting proof references because they observed different batch state at different times.
Document lineage and anchor reuse
Enterprise proof systems also need a clean model for change over time. Documents get amended, certificates get reissued, records get corrected, and none of those events should erase prior evidence.
The right approach is to preserve old proofs and issue new ones with explicit lineage. That gives auditors a history instead of a moving target.
A practical lineage model includes:
| Requirement | Implementation pattern |
|---|---|
| Preserve historical truth | Never delete prior anchors |
| Support corrected documents | Issue new leaf and new anchor association |
| Keep audits readable | Record predecessor and successor references |
| Reduce repeated writes | Use anchor reuse architecture when the same batch commitment supports multiple application records |
Anchor reuse matters when several internal records point to the same underlying document set or event set. One anchored root can support customer-facing attestations, internal compliance evidence, and partner verification workflows, provided the evidence bundle and lineage metadata are kept distinct at the application layer. That cuts chain spend, but it also raises governance questions. Teams need rules for who can associate new business records with an existing anchor, what metadata can change without changing the leaf hash, and when a new root is required for policy reasons rather than technical ones.
Designing those boundaries as separate modules makes the system easier to change under load. A useful pattern is to keep canonicalization, hashing, batching, anchoring, storage, and verification behind clear interfaces, which is the same principle discussed in this article on modular blockchain architecture for scalable proof systems. That separation reduces migration risk when you need to swap hash policies, rotate contracts, or add a new verification channel without invalidating old proofs.
Implementing Scalable Proof Systems with Blocsys
What a delivery partner should handle
Teams that build this in-house usually discover the complexity at the seams. Hashing is straightforward until file formats disagree. Anchoring is straightforward until proof states, retries, and audit exports have to line up. Verification is straightforward until a third party needs a portable evidence bundle that still works outside your platform.
A delivery partner in this area should be able to own the full chain of decisions: canonicalisation policy, hash-only proof API design, Merkle root generation, Polygon L2 attestation contracts, SDK behaviour in browser and Node.js, S3 integration patterns, and verification APIs for external consumers.
One relevant option in this category is Blocsys Technologies, which provides a tamper-proof document verification platform that anchors document hashes to a public blockchain using Merkle tree batching so that thousands of documents can be committed through a single on-chain transaction. That’s useful when you need working blockchain proof infrastructure rather than a proof-of-concept.
The bigger point is architectural discipline. The proof service should stay hash-centric, the chain should hold compact commitments, and the evidence bundle should remain portable across systems and time. The scaling mindset is similar to what teams already apply in distributed platforms. This guide to cloud computing scalability is a useful parallel because proof systems are still pipelines, and pipelines fail when state, throughput, and interface boundaries aren’t designed together.
Frequently Asked Questions about Merkle Batching
What is Merkle batching in simple terms
It’s a way to compress many document or transaction proofs into one on-chain commitment. You hash each item, build a Merkle tree from those hashes, and anchor only the root. Each item then carries a compact inclusion proof back to that root.
How is a Merkle root validated
A verifier recomputes the document hash, walks the sibling hashes in the Merkle proof, reconstructs the root, and checks that the reconstructed root matches the root anchored on-chain.
Can Merkle batching work with private data
Yes. The usual pattern is to keep raw data off-chain and anchor only hashes. The chain proves integrity and existence of the commitment, while the underlying file stays in private storage.
What happens if one document in a batch is invalid
The batch root still exists, but the invalid document won’t verify if its canonical hash or proof path is wrong. One bad leaf doesn’t automatically invalidate every other valid proof in the batch.
Is Polygon L2 a good fit for proof anchoring
It often is for systems that need frequent attestation with lower transaction cost than anchoring every batch on a more expensive layer. The exact choice depends on verification model, trust assumptions, and operational requirements.
If you’re designing a proof pipeline for document verification, compliance evidence, or multi-record attestation, Blocsys Technologies can help you turn the architecture into a production system. That includes hashing rules, batch design, Polygon L2 anchoring, verification APIs, and SDK workflows that hold up under real operational load.