
You hash a contract PDF in Microsoft 365, store the digest, then hash what looks like the same document after it passes through a PDF generator, e-signature tool, or archive system. The hash changes. Legal, security, and engineering teams now have a familiar problem: the document appears identical to a person, but it is no longer identical to a machine.
That gap sits at the centre of how canonicalization makes PDF and Office files hash deterministically in the UK. It matters to cybersecurity teams building tamper-evidence, to compliance teams defending audit trails, and to blockchain teams anchoring document fingerprints on-chain. If your workflow touches PDF, DOCX, XLSX, content management systems, or verification ledgers, deterministic hashing is not an optional refinement. It is the difference between a system that looks rigorous and one that is repeatable.
Table of Contents
- Why Identical Documents Have Different Hashes
- The Hidden Instability in PDF and Office Files
- How Canonicalization Creates a Deterministic Hash
- Standard Hashing vs Canonical Hashing a Comparison
- Using Deterministic Hashes for Blockchain Document Verification
- Importance for UK Compliance and Enterprise Cybersecurity
- How Blocsys Builds Tamper-Proof Document Infrastructure
- Frequently Asked Questions
- What is PDF canonicalization
- How does deterministic hashing work for Office files
- Why do visually identical PDFs produce different hashes
- Does canonicalization remove legally important information
- How does blockchain verify a document without exposing its contents
- Why is this especially relevant in the UK
Why Identical Documents Have Different Hashes
A standard cryptographic hash works exactly as designed. It reacts to every byte in a file. If the bytes differ, the digest differs. That is why two PDFs that look the same on screen can still hash differently.
In practice, teams hit this when a document is opened and re-saved, exported from Word to PDF, routed through a content management platform, or countersigned in a separate tool. The visible wording may not change at all. The internal file representation often does.
For security architects, records managers, blockchain developers, and compliance teams, ordinary file hashing stops being enough. If your control depends on getting the same fingerprint for the same business content, raw hashing won’t reliably survive real document workflows.
Practical rule: If the system hashes the whole byte stream without normalising the file first, it is proving byte identity, not content identity.
That distinction matters more than many teams expect. Byte identity is useful for exact-copy checks. It is poor at handling normal operational movement across PDF exporters, Office saves, archive systems, and document-signing platforms. For tamper detection, legal hold, and duplicate suppression, what you usually need is a stable fingerprint of the document’s meaningful content and structure.
Canonicalization solves that by standardising the representation before hashing. The idea is simple: normalise first, hash second. If two files differ only in non-semantic details, the canonical form should collapse those differences into one stable representation.
This is also why document verification projects often fail when they are designed by analogy to simple file-integrity checks. General hashing is necessary, but it isn’t sufficient for complex office documents. If you want a deeper look at how AI and ledger-based workflows intersect with this problem, Blocsys has a useful piece on detecting fake documents in real time with AI and blockchain.
The Hidden Instability in PDF and Office Files

Why byte-level hashing fails on normal business documents
PDF and Office files are not simple flat text. They are structured containers with metadata, embedded resources, internal references, and serialisation choices that software can rewrite during ordinary use.
Cryptographic work has long treated the separation of content from serialisation as necessary for reliable fingerprinting. Hashes are used for “fingerprinting computer files”, but only after the file is in a stable form, because any change in representation changes the output, as discussed in Bart Preneel’s cryptographic hash reference.
For PDF, the instability often comes from internal object numbering, metadata fields, field ordering, whitespace, compression choices, and object serialisation. For Office files such as DOCX and XLSX, you also have ZIP packaging, XML ordering, application-specific metadata, revision artefacts, and relationships across internal parts.
Where instability enters the workflow
The awkward part is that these changes are usually introduced by tools your organisation already trusts.
- Office save operations: Word, Excel, and PowerPoint may rewrite internal package details when a user opens and saves a file.
- PDF export pipelines: A document exported from Microsoft Office, LibreOffice, or a print-to-PDF driver may render the same content while serialising the internals differently.
- Document systems: Content management, archival, and e-signature tools commonly inject identifiers, timestamps, processing metadata, or object rearrangements.
- Font and resource handling: Embedded fonts, subset naming, and resource packing can differ even where the visible page output appears unchanged.
A document can be visually identical, operationally equivalent, and still fail a raw hash comparison.
That is why teams working on evidence chains, archive fixity, and tokenised document workflows need to think beyond simple SHA-256 over the original file. In real-world asset tokenisation, the legal document and the digital token often need a defensible integrity link. If the hash changes every time the document moves between systems, that link becomes hard to defend.
The operational lesson is straightforward. If your process spans Microsoft 365, PDF conversion, signing, records storage, and later verification, instability is not an edge case. It is the default behaviour unless you deliberately design around it.
How Canonicalization Creates a Deterministic Hash
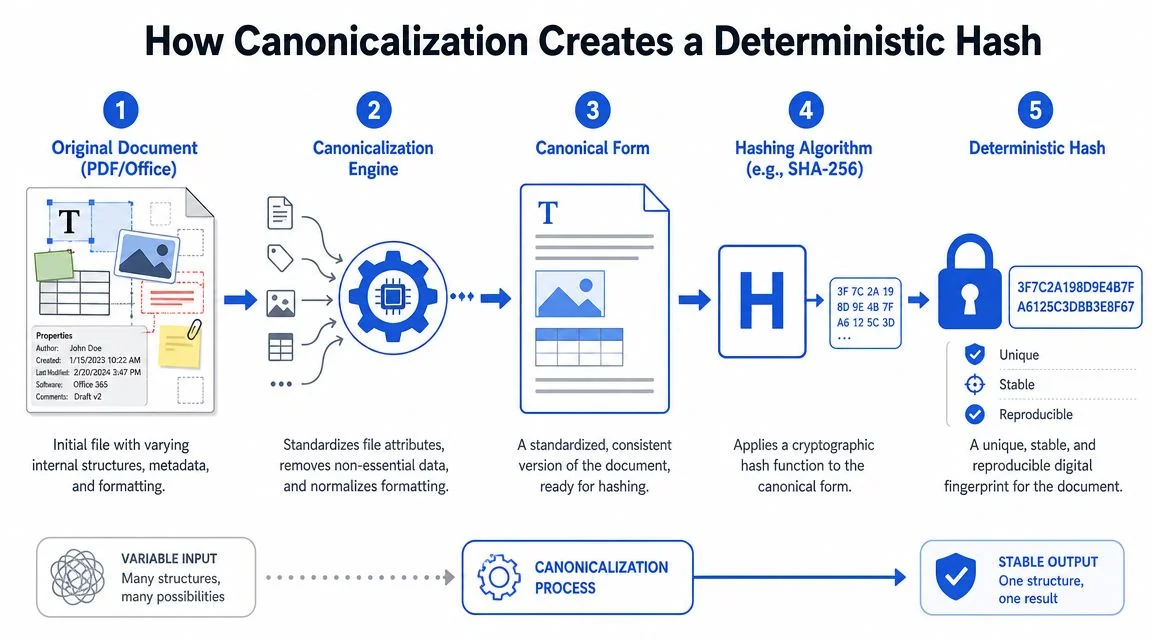
Canonicalization is the process that turns a variable document into a standardised representation before hashing. This is comparable to comparing two recipes after rewriting both into the same format, same ingredient order, same units, same spelling rules. You are no longer comparing formatting accidents. You are comparing the underlying content consistently.
The standards-track version of that idea appears in the W3C’s work on canonicalization and hashing, which describes a way to “uniquely and deterministically calculate a hash” by using deterministic labelling so insignificant differences do not change the digest, as set out in the W3C RDF Dataset Canonicalization and Hash materials. The same principle applies to document workflows: normalise first, then hash.
What canonicalization actually does
A sound canonicalization pipeline defines which differences are irrelevant and which must be preserved. That decision is technical, operational, and sometimes legal.
Common steps include:
- Remove unstable metadata such as fields that reflect save time, generator details, or transient processing values.
- Apply a fixed ordering rule to objects, fields, or internal components so the same content is serialised the same way.
- Normalise formatting noise such as whitespace or equivalent structural representations.
- Preserve legally meaningful content such as signed values, document text, required fields, and provenance elements that must remain evidentially relevant.
- Hash the canonical form with a standard cryptographic function once the representation is stable.
What a production workflow usually normalises
Mature implementations differ from simplistic ones in that a practical design usually separates at least three layers:
| Layer | What to do | Why it matters |
|---|---|---|
| Presentation noise | Normalise or ignore it | Prevent harmless file rewrites from changing the digest |
| Business content | Preserve it | Keep the fingerprint tied to what users and auditors actually care about |
| Provenance fields | Handle by policy | Some fields should be excluded from the content hash but retained in the audit record |
Don’t aim for one universal canonical form across every document type. Aim for a documented canonical policy for each workflow you need to defend.
That matters in the UK because hash-based matching and linkage break down when preprocessing is naïve. The government’s guidance on anonymised data warns that simple hashing on its own is not enough for reliable linkage. The same operational lesson applies to document integrity systems. Determinism depends on disciplined preprocessing, not on the hash function alone.
Standard Hashing vs Canonical Hashing a Comparison
A side-by-side comparison makes the difference clear. Assume you have two contract PDFs. One was exported directly from Word. The other was opened by a signing platform and re-saved with altered metadata and internal object details. A lawyer sees the same contract. Raw hashing sees two different files.
| Attribute | Standard Hashing (SHA-256) | Canonical Hashing (SHA-256) |
|---|---|---|
| Input | Original file bytes | Canonical representation of the file |
| Reaction to metadata changes | Changes the hash | Can be normalised away if policy says metadata is non-semantic |
| Reaction to object ordering differences | Changes the hash | Can be stabilised through fixed ordering rules |
| Suitability for exact-copy checks | Strong | Strong |
| Suitability for cross-system document matching | Weak in mixed toolchains | Stronger when canonical policy is well designed |
| Deduplication value | Limited to byte-identical copies | Better for semantically equivalent files |
| Legal workflow usefulness | Fragile if files are routinely re-saved | More practical when audit rules are documented |
Proofpoint provides a concrete example of this principle in action. Its PDF Object Hashing approach ignores variable object parameters and focuses on the ordered sequence of PDF object types, then hashes that normalised representation so related PDFs can produce the same fingerprint despite differing lure content or metadata, as described in Proofpoint’s PDF Object Hashing write-up.
That example comes from threat hunting, but the pattern transfers well to enterprise document integrity. You define the parts that matter, suppress the parts that don’t, and hash the stable result.
If you need the governance view behind that distinction, this explanation of digital proof of document integrity is a useful companion.
Using Deterministic Hashes for Blockchain Document Verification
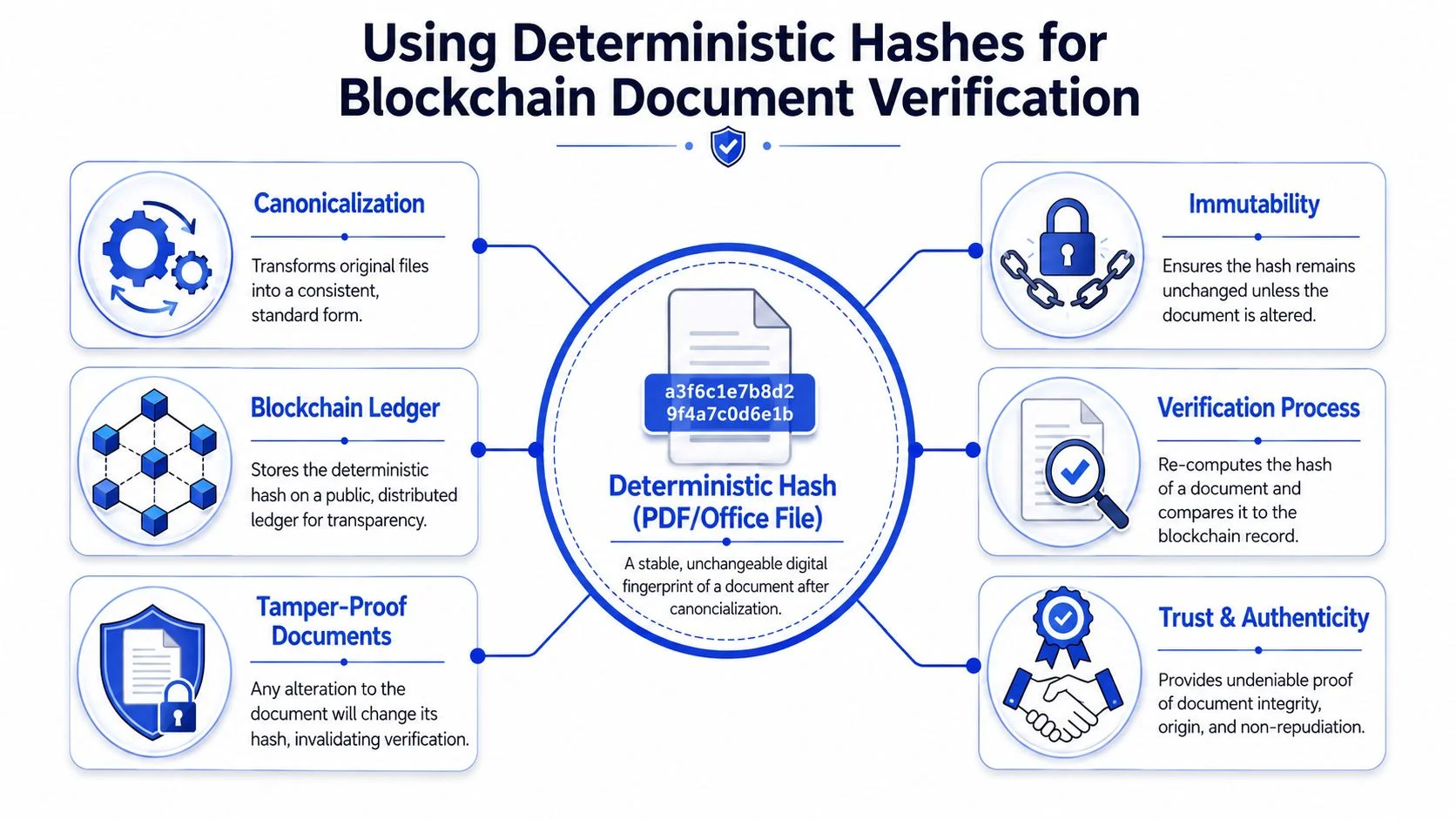
Why blockchain needs a stable fingerprint first
Blockchain does not fix unstable document hashing. It preserves whatever fingerprint you give it. If the fingerprint changes every time the file moves across systems, anchoring that hash on-chain only gives you an immutable record of inconsistency.
That is why deterministic hashing comes first. The W3C working group frames the goal as a standard way to “uniquely and deterministically calculate a hash”, with representation-level variation removed before hashing, which is what makes the result useful for deduplication, fixity checking, and tamper detection across copies, including on systems such as a blockchain, according to the W3C RDF Dataset Canonicalization and Hash Working Group Charter.
A practical verification flow
A workable blockchain document verification system usually follows this path:
- Canonicalise the file: Convert the PDF or Office document into the approved standard form for that workflow.
- Generate the deterministic hash: Hash only the canonical representation.
- Anchor the hash on-chain: Record the digest, timestamp, and related reference data in a ledger transaction.
- Verify later without exposing contents: Recompute the canonical hash from the presented document and compare it with the on-chain record.
- Flag mismatch as integrity failure: If the canonical hash differs, the document has changed or the wrong canonical policy was applied.
This approach is useful for contracts, certificates, onboarding files, regulated disclosures, and internal approvals. It also avoids a common privacy mistake. You generally don’t need to publish the document itself to the chain. You anchor the fingerprint and keep the source document in controlled storage.
Blockchain gives you durable evidence of a fingerprint. Canonicalization gives you a fingerprint worth trusting.
For teams building public verification or QR-linked authenticity checks, the process works well when the verification client knows exactly how to canonicalise the file before recomputing the hash. That is where many pilots fail. They build the ledger write first and leave the canonical policy vague. For a practical example of how public verification flows can work in business settings, see this guide to QR codes with blockchain document authentication in the UK.
Importance for UK Compliance and Enterprise Cybersecurity
Why UK organisations care about repeatable integrity checks
In the UK, the business case for deterministic hashing is not abstract. Organisations need records they can defend, not just store. That affects legal evidence, internal investigations, cyber response, regulated recordkeeping, and cross-system auditability.
The pressure is rising. The UK government’s 2024–2025 Cyber Security Breaches Survey found that 50% of businesses reported a cyber breach or attack in the previous 12 months, and 74% of large businesses had a formal cyber security strategy, as discussed in the survey analysis published in PMC. When firms formalise cyber strategy, document integrity becomes part of the control environment. It is no longer enough to say a file was stored securely. Teams need to show whether it is the same document, when it changed, and whether the proof is repeatable.
In legal and regulated environments, that repeatability matters because audit trails are only useful if another team can reproduce the same result later. A hash that changes because a document moved through a different export pipeline is hard to use as durable evidence.
Where teams get the design wrong
The most common mistake is to treat document hashing as a single technical feature instead of a controlled process. In practice, UK organisations need policy decisions around what gets normalised, what remains evidential, who approves canonical rules, and how verification is logged.
Typical failure points include:
- Over-normalising the file: Removing fields that later turn out to matter in a dispute.
- Under-normalising the file: Leaving enough serialisation noise in place that equivalent files still hash differently.
- Ignoring data governance: Deterministic hashing does not replace privacy, retention, and access controls. Teams working through SaaS and records issues should also understand how GDPR affects your SaaS tools.
- Treating verification as one-time: Real integrity systems need re-verification across system migrations, archive transfers, and investigations.
A mature design ties hash determinism to broader identity and trust workflows. That is why the same principles also appear in employee verification, onboarding, and records assurance. This example of blockchain verification for hiring and employee background checks shows how repeatable integrity logic carries into adjacent compliance use cases.
How Blocsys Builds Tamper-Proof Document Infrastructure
A UK legal team usually discovers the gap at disclosure time, not at deployment time. The document looks unchanged, the business process says it is the same record, but the exported file hash no longer matches what was stored months earlier. At that point, the question is no longer technical. It is whether the organisation can show a clear, repeatable integrity process that stands up in audit, litigation, or regulatory review.
Building that kind of system takes more than a hashing feature inside a workflow tool. It requires controlled canonical rules for PDF and Office formats, consistent proof generation, and evidence records that show who verified what, when, and under which policy version. In UK environments, that matters for records management, evidential weight, and internal accountability as much as for cyber controls.
The implementation usually has four parts:
- Canonicalization policy design: Define which PDF and Office changes are treated as packaging noise, which fields remain evidential, and how exceptions are approved.
- Deterministic hashing and proof generation: Hash the canonical form so equivalent documents produce the same fingerprint across export tools and storage systems.
- Evidence architecture: Preserve verification logs, timestamps, policy references, and chain-of-custody records so an auditor can reconstruct the decision path.
- Ledger anchoring at scale: Anchor proofs efficiently when verification volumes rise, especially in archive, contract, HR, or regulated document flows.
For teams mapping this into governance and assurance work, this guide to UK compliance reporting is useful context because a defensible document proof still has to fit into a wider reporting and control framework.
Blocsys Technologies is one provider working in this area, building blockchain and AI infrastructure that can support document-proof workflows, immutable verification records, and later re-checks against anchored proofs. At enterprise volume, single-document anchoring becomes expensive and operationally awkward, which is why Merkle batching for one-chain transaction across thousands of proofs matters in production designs.
The practical design choice is straightforward. Start with the canonical policy, tie it to retention and evidence requirements, then build the proof and verification flow around your document lifecycle. That is what turns a hash into something a UK organisation can rely on.
Frequently Asked Questions
What is PDF canonicalization
PDF canonicalization is the process of converting a PDF into a standardised representation before hashing. It reduces non-semantic differences such as metadata or structural serialisation quirks so that equivalent documents can produce the same deterministic fingerprint.
How does deterministic hashing work for Office files
It works by separating meaningful content from unstable packaging details. For Office documents such as DOCX or XLSX, the workflow usually normalises internal structure, metadata, and ordering rules before applying the cryptographic hash to the canonical form.
Why do visually identical PDFs produce different hashes
Because raw hashing reacts to byte-level differences, not human visual similarity. Two PDFs can display the same text and layout while differing internally due to metadata, object numbering, export settings, or other serialisation changes.
Does canonicalization remove legally important information
It shouldn’t if it is designed properly. The hard part is policy design. A defensible system removes non-semantic variation while preserving text, required fields, provenance elements, and any artefacts that matter for audit, evidence, or dispute resolution.
How does blockchain verify a document without exposing its contents
The workflow anchors the document’s deterministic hash on-chain rather than storing the full file publicly. Later, the verifier canonicalises the document again, recomputes the hash, and checks whether it matches the on-chain record.
Why is this especially relevant in the UK
UK organisations increasingly need repeatable integrity controls across cybersecurity, audit, legal, and digitised records workflows. Deterministic hashing fits that need because it supports stable verification across mixed document systems, which raw file hashing often cannot do reliably.
If your team needs a practical path from unstable file hashes to defensible document verification, Blocsys Technologies can help you design the canonicalization rules, proof architecture, and blockchain verification flow around your actual document lifecycle. For early scoping, you can also use the software development cost estimator to map likely implementation effort before moving into architecture and delivery.