
You’re probably seeing the same pattern in more than one product line. A customer uploads a document your platform has already verified. A compliance team approves the same evidence package for another workflow. A marketplace references the same asset metadata across issuance, custody, and reporting. Yet the system still pushes a fresh on-chain write as if the content were new.
That’s the expensive mistake.
In web architecture, teams already know that duplicate content shouldn’t be handled as if every copy were a separate asset. Search guidance recommends unique URLs and crawlable navigation instead of repeated anchor-based sections that blur page identity for indexers, and where overlap is unavoidable, stronger consolidation patterns like canonicals or redirects reduce conflicting signals and keyword cannibalisation (Search Engine Journal, SEO Sherpa). On-chain systems need the same discipline, but applied to state changes rather than crawl logic.
That’s the key idea behind Anchor Reuse: When Duplicate Content Should Not Pay Gas Again. If the underlying content is the same, the chain should usually reference an existing proof state, not create a new one. For CTOs building verification rails, document platforms, exchange infrastructure, or compliance workflows, this is less an optimisation trick and more a design rule.
Table of Contents
- The High Cost of Redundancy in Enterprise Blockchain
- What Is Blockchain Anchor Reuse
- How Deterministic Hashing Creates a Unique Content Fingerprint
- The Metadata Anchoring and Verification Workflow
- Enterprise Use Cases for Gas-Efficient Verification
- Comparison Anchor Reuse vs Traditional On-Chain Data Storage
- Build Your Gas-Efficient Platform with Blocsys
- Frequently Asked Questions about Anchor Reuse
The High Cost of Redundancy in Enterprise Blockchain
A bank verifies the same KYC packet during onboarding, then verifies it again for audit, then again when a lending partner requests proof. If each check triggers a new on-chain write, the platform pays gas three times for one underlying fact. That is the blockchain version of duplicate content. The information is the same, but the system keeps publishing it as if it were new.
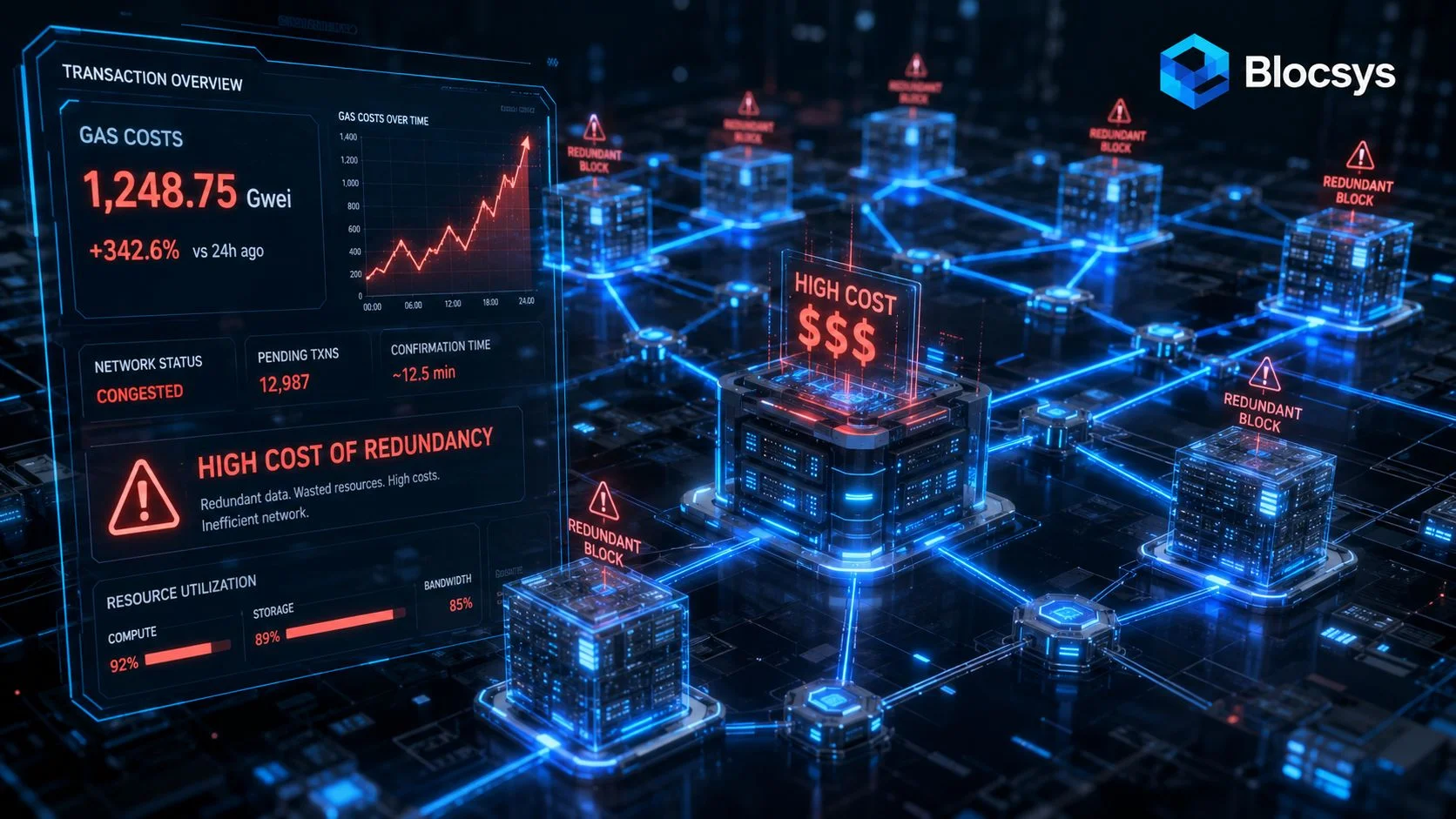
This problem shows up in enterprise systems far more often than smart contract teams expect. The cost is not only gas. Redundant writes increase reconciliation work, create duplicate proof objects to manage, and make it harder to explain system behavior to auditors and counterparties.
Where gas waste actually shows up
The pattern is usually operational, not cryptographic:
- Repeated document anchoring: The file has not changed, but separate departments submit it as a new record.
- Duplicate compliance attestations: The same approved evidence package is written again across adjacent workflows.
- Multi-tenant platforms with shared artefacts: One verified item is used by many parties, but the contract stores each use as a separate proof entry.
- Operational retries: Front ends, job workers, or partner integrations resend the same payload, and the contract accepts every write.
The design rule is straightforward. If the underlying content and its verification outcome have not changed, a new state write needs justification.
A useful way to frame this is with the web concept of duplicate content. In web architecture, repeated copies of the same page create indexing and canonicalization problems. On-chain, repeated copies of the same proof create cost and state management problems. The shared lesson is architectural. Systems need a canonical representation of one thing, then a reliable way to reference it many times.
A product decision is often overlooked
Teams often model every user action as a new blockchain event, even when the action does not introduce a new truth. That choice is expensive in high-volume platforms. Verification products, supplier portals, trade document networks, and media rights systems all see the same pattern. The business process repeats, but the content fingerprint does not.
The better approach is to separate reuse from change. A repeated verification request can point to an existing proof. A changed file, changed metadata policy, or changed legal status can create a new on-chain state transition. That distinction keeps contracts smaller, gas spend lower, and audit logic easier to defend.
For enterprise architects, this is the practical takeaway. Do not treat every repeated submission as a storage problem. Treat it as a lookup problem first. In systems with sustained volume, reference models, cached proofs, and batched verification patterns such as Merkle batching for thousands of proofs usually produce a better cost profile than write-everything designs.
What Is Blockchain Anchor Reuse
Blockchain anchor reuse means recording a content proof once, then referencing that existing proof whenever the same content appears again.
At the implementation level, an anchor is usually a compact on-chain record. It often contains a hash of the content plus a small amount of metadata needed for later verification. The content itself stays off-chain.
Anchor first, content second
The easiest analogy is a library reference. You don’t ship the whole book every time someone wants to cite one sentence. You point them to the catalogue entry, edition, and page.
That’s what anchor reuse does for digital content. The first valid version of a file, certificate, image, or data package gets hashed and anchored. Every later workflow checks whether that fingerprint already exists. If it does, the system reuses the anchor.
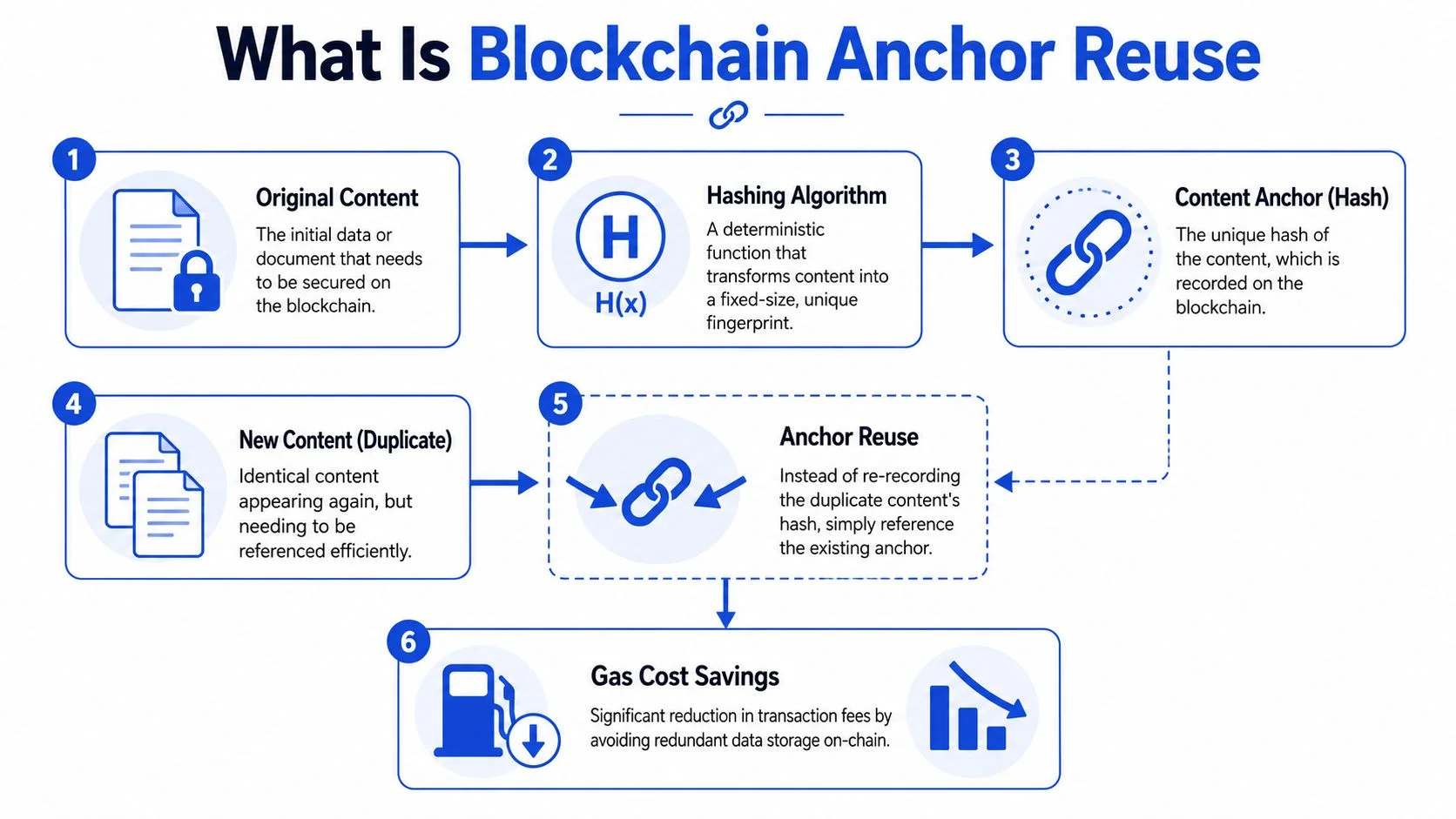
The operational consequence is important. You stop treating “same content, new submission” as a storage event. You treat it as a lookup and reference event.
A useful implementation note is in why local hashing and metadata-only submission matters. That model keeps sensitive payloads out of unnecessary transmission paths and makes the anchor small enough to reuse efficiently.
What reuse means in practice
Anchor reuse is not “never write to chain again”. It means writing only when the state is substantially new.
The decision usually looks like this:
- Hash the submitted content.
- Check whether that hash already has a valid anchor.
- If it exists, attach the business event to the existing proof.
- If it doesn’t, create a new anchor once.
Later in the workflow, this explainer gives a concise visual summary:
Reuse is a contract design choice, not a user-interface shortcut. If the contract doesn’t model referenceability, the front end can’t save you.
How Deterministic Hashing Creates a Unique Content Fingerprint
Anchor reuse only works if every participant can derive the same identity for the same content. That’s why deterministic hashing sits at the centre of the design.
A deterministic hash function always produces the same output for the same input. Feed in the same contract PDF, image, or JSON payload and you get the same fingerprint every time. Change even a tiny part of the content and the output changes as well.
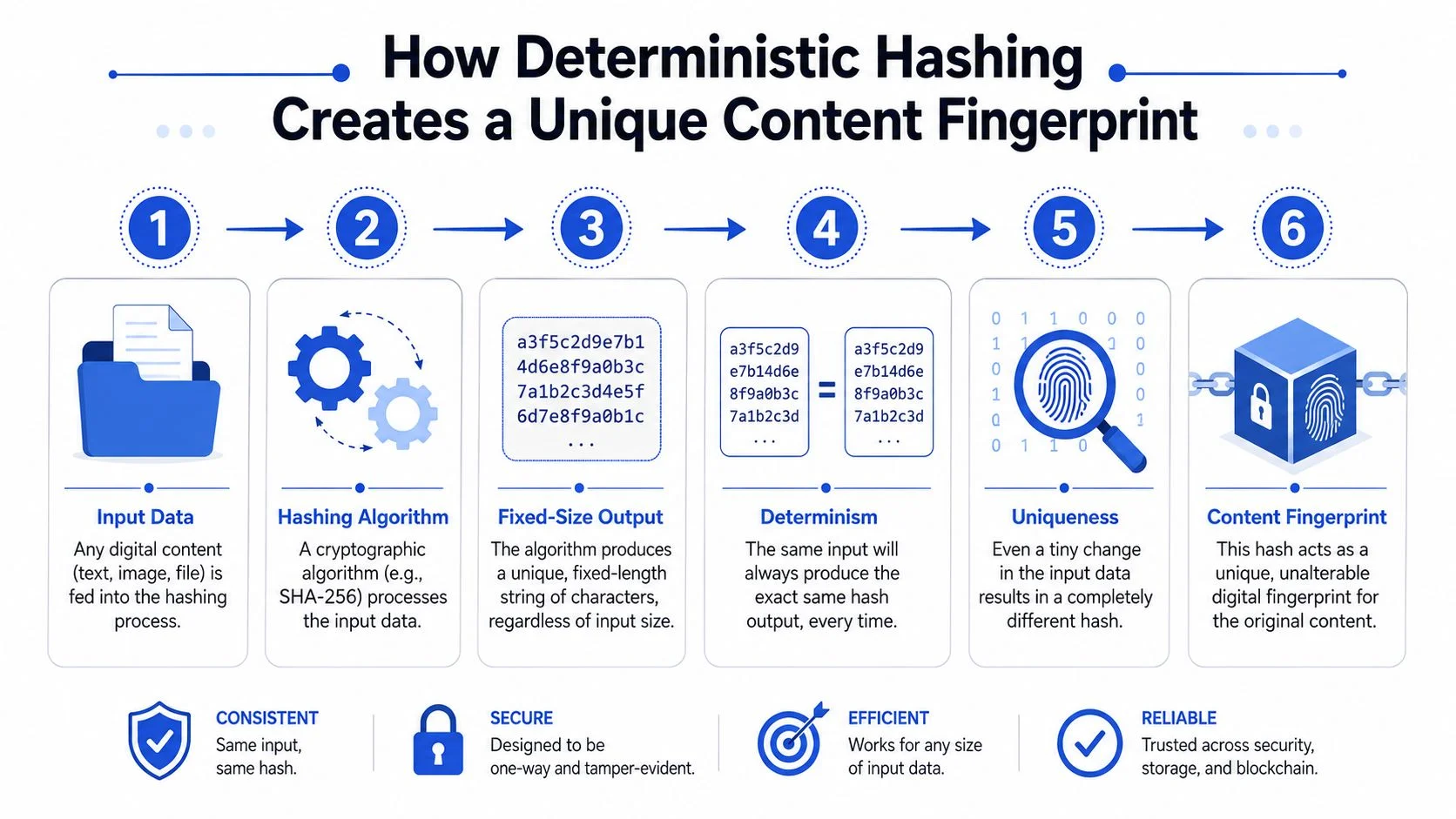
Why determinism matters operationally
For a CTO, the value isn’t academic. Determinism is what lets different systems agree that two submissions are the same artefact.
That supports several critical behaviours:
- Cross-channel consistency: A web portal, mobile app, partner API, and internal operations tool can all arrive at the same content fingerprint.
- Deduplication before spend: The application can check for an existing anchor before it initiates a paid state change.
- Independent verification: A regulator, customer, or downstream platform can recompute the fingerprint without trusting your database.
If you’re dealing with PDFs, Office files, or generated reports, you also need to control canonicalisation. File formats often contain hidden variability such as metadata ordering, timestamps, or export differences. The practical fix is to normalise content before hashing, which is the core idea behind deterministic hashing through canonicalisation for PDFs and Office files.
What breaks the model
Most failed anchor reuse implementations don’t fail because hashing is weak. They fail because inputs aren’t stable.
Watch for these problems:
- Unnormalised file generation: Two visually identical documents can hash differently if export tooling injects variable metadata.
- Mixed hashing rules across services: If one service hashes raw bytes and another hashes transformed payloads, deduplication fails.
- Overloading the hash with business context: The content fingerprint should identify the content. Business events should sit beside it, not inside it.
- Hashing after mutation: Watermarking, redaction, compression, or format conversion after user submission changes the fingerprint and breaks reuse.
A clean design separates concerns. One layer answers, “Is this the same content?” Another answers, “What business event is associated with it?”
The Metadata Anchoring and Verification Workflow
The workflow is straightforward when the architecture is disciplined. It becomes messy when teams mix storage, verification, and event logging into one contract.
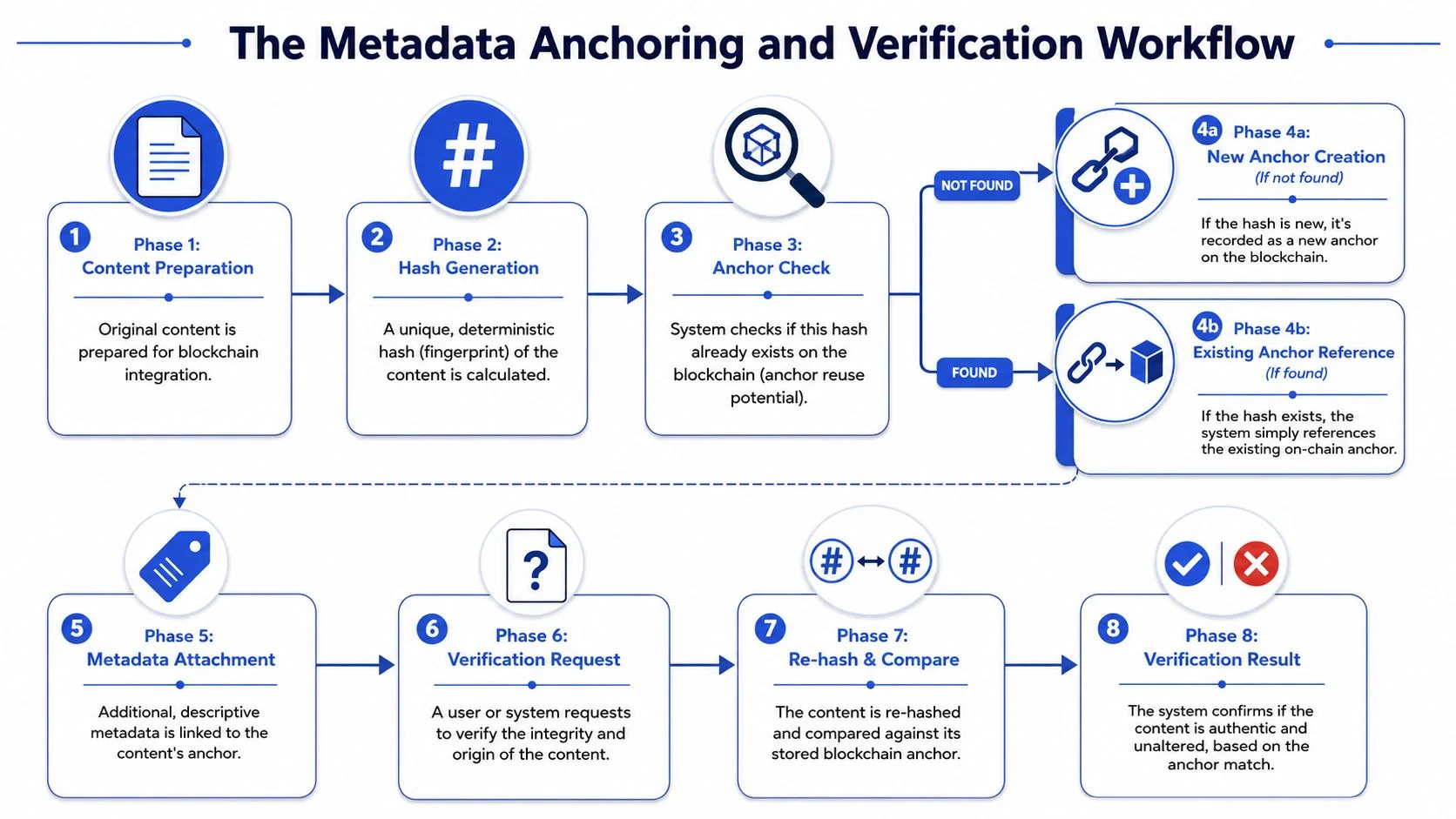
The decision tree that saves gas
A production-ready flow usually follows this order:
- Content arrives off-chain. It may be a contract, certificate, invoice, rights asset, or compliance file.
- The application canonicalises the payload. This step ensures equivalent inputs become identical before hashing.
- A deterministic hash is generated. This becomes the candidate anchor key.
- The system checks for an existing on-chain anchor. This can happen through a contract mapping, an indexer, or a contract-plus-cache pattern.
- A branch decision follows.
- If the hash is already anchored, the platform references the existing record.
- If the hash is new, the platform creates a one-time anchor transaction.
- Business metadata is attached. That may include issuer identity, workflow context, or permissioning references.
- Later verification re-hashes the content and compares it to the anchor.
- The platform returns an authenticity result.
In document-heavy systems, the automation layer is as important as the chain interaction. A reliable reference design looks a lot like the workflow behind smart-contract-driven document authentication, where the contract proves integrity while application services manage access, indexing, and policy.
What metadata belongs on-chain
In these cases, teams often overbuild.
The chain should store only what needs tamper resistance or public verifiability. Everything else should remain off-chain in systems built for search, permissioning, and lifecycle management.
A practical split looks like this:
| Layer | Good candidates |
|---|---|
| On-chain | Content hash, anchor identifier, minimal issuer reference, verification timestamp, revocation or status flags |
| Off-chain | Full document payload, user profile data, workflow notes, routing history, internal audit comments |
| Hybrid | Encrypted references, storage locators, tenant-scoped metadata, compliance tags |
Store proof on-chain. Store business convenience off-chain.
That separation gives you a cleaner privacy posture, smaller contracts, and faster verification logic. It also makes upgrades easier. Business metadata changes often. Proof semantics usually shouldn’t.
Enterprise Use Cases for Gas-Efficient Verification
The strongest anchor reuse architectures appear in systems where the same artefact is consumed many times by different parties.
Document verification across repeated checks
Consider a credentials platform serving universities, employers, and regulated institutions. A diploma or training certificate may be issued once but checked repeatedly across admissions, hiring, mobility, and audit processes.
The wrong model creates a fresh on-chain proof every time another relying party asks the same question. The better model anchors the credential once, then lets each verification event reference that proof. Employers don’t need a new chain write to learn that the document matches the original fingerprint. They need a trustworthy lookup path.
This is the same logic that helps banks handle customer records more efficiently in blockchain-backed customer document verification workflows. The key gain isn’t just lower gas. It’s a cleaner operating model where repeated checks don’t inflate state.
Supply chain provenance without duplicate attestations
Now take a pharmaceutical or high-value manufacturing chain. A certificate of analysis, inspection record, or custody statement may follow a batch across several counterparties.
Each participant needs to verify the artefact, but they don’t need to re-anchor identical content each time it changes hands. Anchor reuse gives downstream partners a stable proof object. They can attach their own workflow events, acceptance steps, or handover records without treating the original certificate as new content.
That distinction keeps provenance systems from collapsing into repetitive proof storage. It also reduces disagreement. Everyone references the same anchored artefact instead of creating competing versions of “truth”.
Rights and media proofs without re-anchoring the file
Media platforms, licensing systems, and brand protection tools face a related issue. A creator wants to establish that a high-resolution image, audio file, or design existed in a particular form at a particular time. They do not want to place the file itself on-chain, and they shouldn’t need a fresh anchor every time the asset is licensed, distributed, or inspected.
A better architecture hashes the original file, anchors the proof, and treats later commercial actions as references to that proof state. Ownership claims, usage permissions, marketplace listings, and audit trails can all point back to the same underlying anchor.
Anchor reuse becomes more than a gas tactic. It becomes the foundation for composable trust across organisations.
Comparison Anchor Reuse vs Traditional On-Chain Data Storage
A common failure mode shows up after launch. A team starts by writing each document interaction on-chain because it feels safer, then six months later they realise they built a duplicate content engine for a system that charges per state change.
That is the right frame for this comparison. Traditional on-chain storage treats every resubmission, retry, or handoff as new state. Anchor reuse treats unchanged content as the same artefact and asks a narrower question: does this action create new business state, or is it only another reference to an existing proof?
Architecture comparison
| Metric | Anchor Reuse Model | Traditional On-Chain Storage |
|---|---|---|
| Gas behaviour | Pays once for a new content anchor, then references it for repeats | Pays again whenever the application writes duplicate or unchanged content |
| Scalability | Holds up well in multi-party workflows where the same artefact is checked many times | Costs rise with every repeated submission, sync job, and retry |
| Verification flow | Recompute the hash, resolve the existing anchor, validate metadata | Mixes proof creation and proof checking into the same write-heavy path |
| Privacy posture | Stores minimal proof data on-chain and keeps source content off-chain | Increases the chance that excess data or metadata ends up permanently visible |
| Contract design | Needs deterministic hashing, anchor lookup, and reference logic | Easier to prototype, but expensive and messy under production volume |
| Operational clarity | Separates content identity from workflow events and approvals | Blurs the line between storage, proof, and business process history |
| Failure handling | Retries are easier to make idempotent because the anchor already exists | Retries often create duplicate records unless every caller is carefully controlled |
The cost difference is not only technical. It changes product economics. In a banking or trade-finance workflow, the same statement, KYC package, or signed disclosure may be checked by several internal systems and external parties. Writing each check as new chain state creates cost without adding truth. The broader direction of financial infrastructure points the other way, toward reusable verified artefacts and selective state changes, which is part of why the discussion around AI and blockchain in banking keeps returning to verifiable data pipelines instead of indiscriminate on-chain storage.
Where traditional storage still makes sense
Traditional on-chain writes are justified when the system is recording something new, not merely seeing the same content again.
- The underlying content changed. A revised certificate, amended loan file, or updated policy document needs a new fingerprint and a new on-chain record.
- The legal meaning changed. A new approval, countersignature, or regulated attestation is a separate event even if it references the same source file.
- Independent sequencing matters. Settlement steps, order events, and nonce-sensitive operations often need distinct records for control reasons.
- Access, revocation, or liability differs by context. Reusing one anchor across all contexts can be the wrong model if each proof object carries different obligations.
The practical rule is simple. Charge gas for new truth. Reuse anchors for duplicate content.
Build Your Gas-Efficient Platform with Blocsys
Designing anchor reuse into production infrastructure isn’t just about writing a hash to a contract. The hard part is making the full system deterministic, observable, and safe under real traffic.
What a production architecture requires
A workable platform needs several layers to cooperate:
- Canonicalisation services so equivalent files hash identically
- Smart contracts that distinguish new anchors from reusable ones
- Indexing and lookup paths that keep duplicate detection fast
- Metadata policy that decides what belongs on-chain and what doesn’t
- Audit and revocation logic for regulated workflows
- Retry-safe APIs so operational noise doesn’t create duplicate state
Many teams often underestimate complexity. The contract may be small, but the reliability envelope isn’t. Cross-region uploads, partner integrations, asynchronous queues, and enterprise permissions all shape whether anchor reuse works.
Where Blocsys fits
That’s the gap Blocsys is built to close. Teams that need enterprise blockchain solutions rarely need a toy verifier. They need a platform that can support tokenisation, exchanges, document integrity, and intelligent compliance without turning every repeated action into a paid state write.
For companies that already know the architecture they want, Hire Blockchain Developers is the direct route to implementing deterministic hashing, verification contracts, and gas-conscious infrastructure. If the scope is still taking shape, the software development cost estimator is a practical way to frame delivery before committing engineering time.
Frequently Asked Questions about Anchor Reuse
What happens if the off-chain data is lost
The on-chain anchor still proves that a specific fingerprint existed, but you can’t re-verify the original content if the source file is gone. That’s why anchor reuse should always sit beside durable storage, backup policy, and clear retention controls. The chain proves integrity. It doesn’t replace content stewardship.
Can this work with IPFS or a data availability layer
Yes, provided responsibilities stay clear. IPFS or a data availability layer can help with storage and retrieval. The anchor still acts as the integrity checkpoint. In well-designed systems, storage location and proof identity are related but not confused. One answers where content can be fetched. The other answers whether content matches the expected fingerprint.
Can any EVM-compatible chain support this pattern
In general, yes. The core requirements are modest: deterministic hashing off-chain, a contract or index path that can check whether an anchor already exists, and a reference model for later events. What changes by chain is cost profile, finality behaviour, tooling, and the operational design around indexing.
When should a repeated action create a new transaction
Create a new transaction when the action changes legal, financial, or operational state in a way that must stand on its own. Don’t create one just because the same file showed up twice. A second approval, a revocation, or a transfer of responsibility may deserve a new transaction. A duplicate integrity check usually doesn’t.
If you’re deciding between reuse and a new write, this filter works well:
- Same content, same proof intent: Reuse the anchor.
- Same content, new business event: Reference the anchor and log the event separately.
- Changed content: Create a new anchor.
- Same content, new liability or attestation boundary: Consider a new transaction, but keep the content proof distinct from the event itself.
The deeper design lesson mirrors what search teams already know. Duplicate artefacts should be consolidated instead of treated like independent assets. In SEO, that means canonical signals and clean site structure. In blockchain, it means referenceable proof states instead of duplicate execution. That’s the practical meaning of Anchor Reuse: When Duplicate Content Should Not Pay Gas Again.
If you’re building a verification platform, exchange workflow, or enterprise document authentication system, Blocsys Technologies can help you design deterministic hashing, reusable on-chain anchors, and gas-efficient blockchain infrastructure that scales cleanly. Connect with Blocsys to plan the architecture, estimate delivery, or bring in experienced engineers for implementation.